Drive AI development and deployment while safeguarding all stages of the AI lifecycle.
Powered by NVIDIA NIM microservices, the Cloudera AI Inference service delivers market-leading performance—delivering up to 36x faster inference on NVIDIA GPUs and nearly 4x the throughput on CPUs—streamlining AI management and governance seamlessly across public and private clouds.
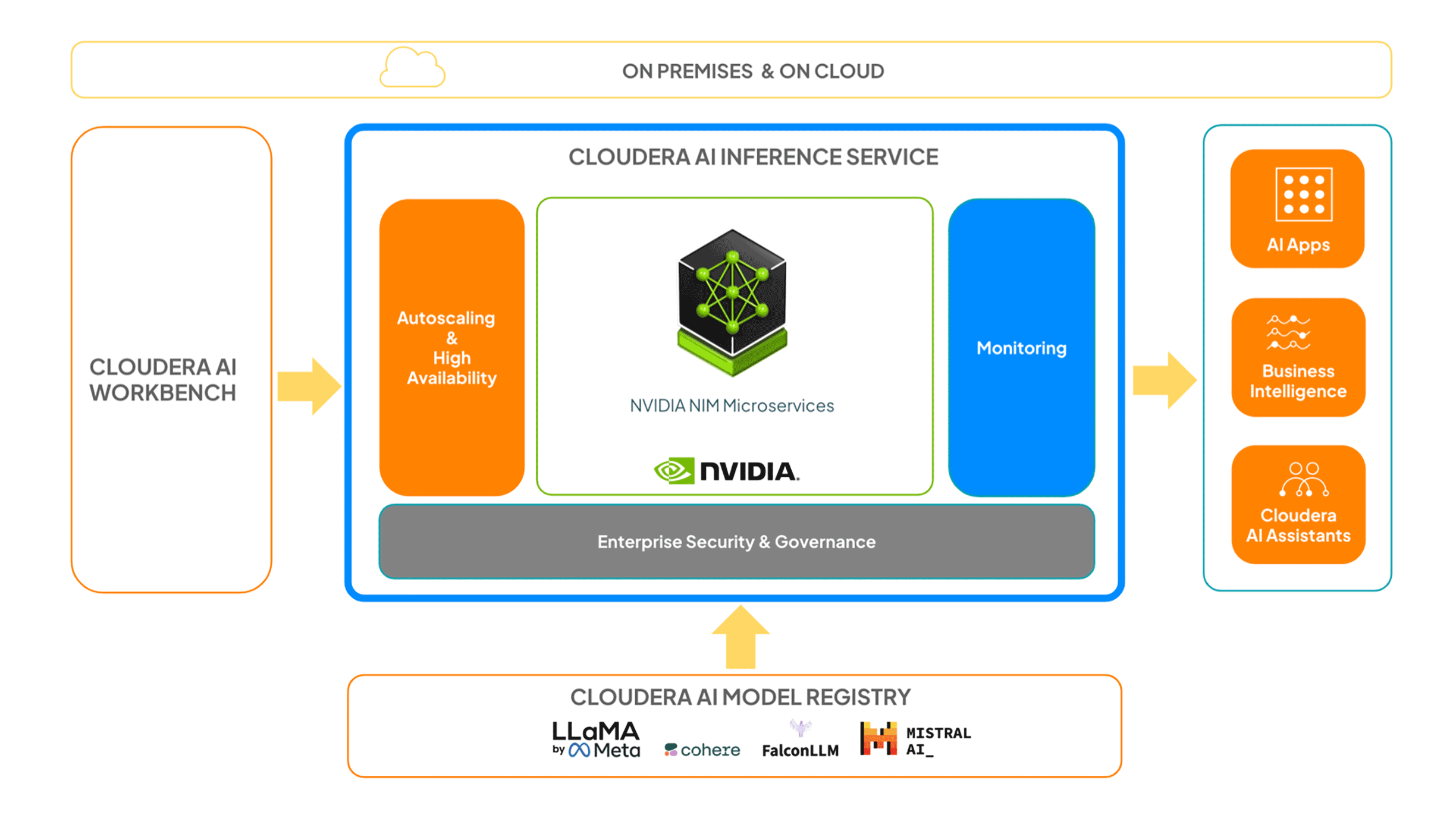
One service for all your enterprise AI inference needs
One-click deployment: Move your model from development to production quickly, regardless of environment.
One secured environment: Get robust end-to-end security covering all stages of your AI lifecycle.
One platform: Seamlessly manage all of your models through a single platform that handles all your AI needs.
One-stop support: Receive unified support from Cloudera for all your hardware and software questions.
Demo
Experience effortless model deployment for yourself
See how easily you can deploy large language models with powerful Cloudera tools to manage large-scale AI applications effectively.
Model registry integration: Seamlessly access, store, version, and manage models through the centralized Cloudera AI Registry repository.
Easy configuration & deployment: Deploy models across cloud environments, set up endpoints, and adjust autoscaling for efficiency.
Performance monitoring: Troubleshoot and optimize based on key metrics such as latency, throughput, resource utilization, and model health.

Get engaged
Blogs
From Machine Learning to AI: Simplifying the Path to Enterprise Intelligence
Predictive Models Are Nothing Without Trust
Introducing Accelerator for Machine Learning (ML) Projects: Summarization with Gemini from Vertex AI
Documentation
Resources and guides to get you started
Ready to get started?
Let’s connect.